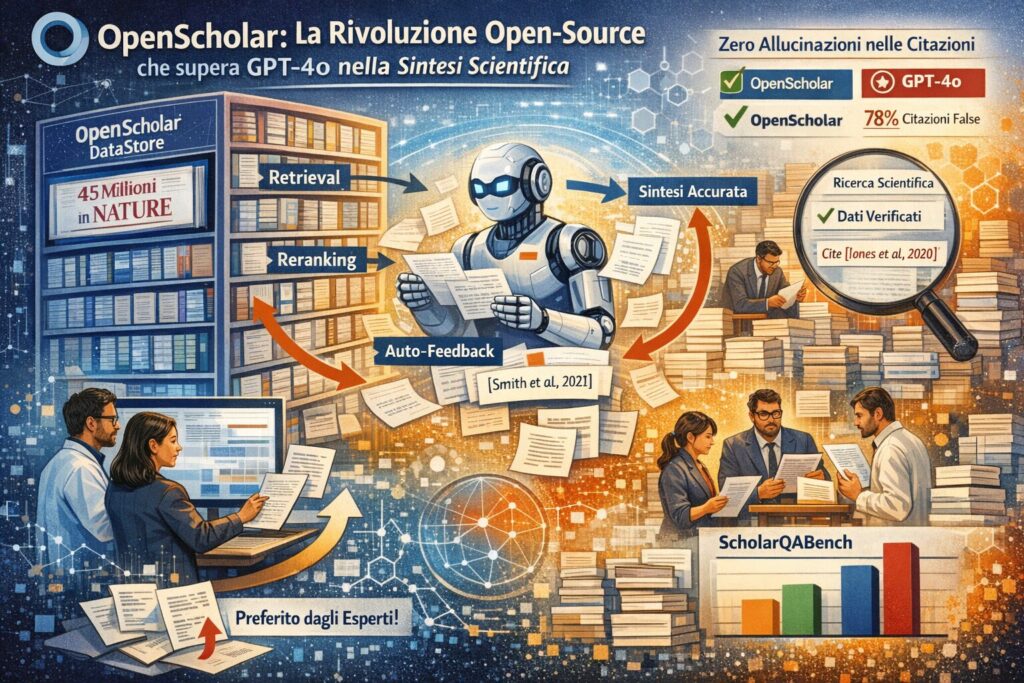
Il progresso della scienza moderna è paradossalmente ostacolato dalla sua stessa fecondità poiché la crescita esponenziale della letteratura accademica rende quasi impossibile per i ricercatori rimanere aggiornati su ogni nuova scoperta. In questo scenario critico, un team di scienziati guidato da Akari Asai e Hannaneh Hajishirzi ha presentato sulla prestigiosa rivista Nature il progetto OpenScholar, un sistema di intelligenza artificiale progettato specificamente per la sintesi della letteratura scientifica. A differenza dei modelli generici, OpenScholar non si limita a generare testo plausibile ma interroga un database specializzato di 45 milioni di articoli ad accesso aperto per fornire risposte basate su prove concrete. La portata di questa innovazione risiede nella sua natura completamente aperta, offrendo alla comunità scientifica uno strumento trasparente e riproducibile che sfida il dominio dei modelli commerciali proprietari.
Il superamento delle allucinazioni e il trionfo della precisione citazionale
Uno dei problemi più gravi che affliggono i modelli linguistici di grandi dimensioni come GPT-4o è la tendenza a fabbricare riferimenti bibliografici inesistenti, un fenomeno noto come allucinazione delle citazioni. Lo studio rivela dati allarmanti: nelle prove sperimentali, GPT-4o ha generato citazioni false in una percentuale compresa tra il 78% e il 90% dei casi quando interrogato su letteratura recente. Al contrario, OpenScholar raggiunge un’accuratezza citazionale paragonabile a quella degli esperti umani, eliminando quasi totalmente il rischio di riferimenti fittizi. Questo risultato straordinario è possibile grazie all’integrazione di un ciclo di auto-feedback e verifica che raffina iterativamente le risposte, assicurando che ogni affermazione scientifica sia rigorosamente supportata da un passaggio estratto dai documenti reali.
L’architettura OpenScholar tra DataStore specializzato e cicli di feedback
Il cuore tecnologico di questo sistema è l’OpenScholar DataStore (OSDS), una base di conoscenza immensa che comprende oltre 236 milioni di passaggi testuali estratti da pubblicazioni scientifiche aggiornate. Il processo di elaborazione di una query non è lineare ma ciclico: il modello prima recupera i documenti rilevanti tramite un retriever addestrato, poi raffina la selezione con un reranker e infine genera una bozza iniziale. A questo punto interviene il meccanismo di self-feedback, in cui il modello stesso identifica lacune o necessità di approfondimento, formulando nuove sotto-query per arricchire la risposta finale. Questo approccio iterativo permette di ottenere sintesi di lunga forma che non solo sono corrette, ma anche complete e ben organizzate, superando i limiti dei sistemi RAG standard.
ScholarQABench il nuovo standard per la valutazione della sintesi scientifica
Per testare le capacità di questo nuovo strumento, i ricercatori hanno sviluppato ScholarQABench, il primo benchmark multidisciplinare su larga scala dedicato specificamente alla ricerca bibliografica. Questo strumento di valutazione comprende quasi 3.000 query scritte da esperti in campi diversi come la neuroscienza, la biomedicina, la fisica e l’informatica. A differenza dei test precedenti basati su risposte brevi o scelta multipla, ScholarQABench richiede risposte articolate e complesse, testando la capacità dell’IA di ragionare su più articoli contemporaneamente. I risultati mostrano che anche la versione compatta del modello, OpenScholar-8B, supera GPT-4o del 6,1% in termini di correttezza e il sistema specializzato PaperQA2 del 5,5%.
La preferenza degli esperti umani e l’impatto sulla ricerca futura
L’aspetto forse più sorprendente dello studio riguarda la valutazione soggettiva condotta da scienziati con titoli di Ph.D., i quali hanno confrontato le risposte dell’IA con quelle scritte da colleghi umani. Gli esperti hanno preferito le risposte generate da OpenScholar-GPT-40 rispetto a quelle scritte da esseri umani nel 70% dei casi, e quelle della versione OpenScholar-8B nel 51% dei casi. Questa preferenza è dovuta principalmente alla capacità del modello di offrire una maggiore copertura informativa e una profondità di analisi che spesso sfugge anche a un esperto che dedica un’ora alla stesura di una singola sintesi. Nonostante questi successi, gli autori sottolineano che l’IA non può ancora automatizzare completamente la sintesi scientifica e che restano sfide aperte nell’identificazione dei lavori più seminali o nell’integrazione di contenuti protetti da copyright. La decisione di rilasciare tutto il codice, i dati e i modelli in modalità open-source rappresenta dunque un invito globale alla collaborazione per affinare ulteriormente strumenti che potrebbero accelerare drasticamente il ritmo della scoperta scientifica.
 Vuoi ricevere le notifiche sulle nostre notizie più importanti?
Vuoi ricevere le notifiche sulle nostre notizie più importanti?